
2026年06月15日(月)
チェッカーズ!
文法でなく文脈で~テキストマイニングの新手法が言語の壁を超える



- TOP
- >
- 文法でなく文脈で~テキストマイニングの新手法が言語の壁を超える
新着ニュース30件
[PR]
2010年6月15日 11:00
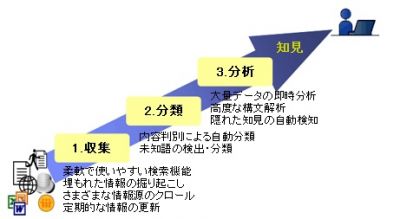
この「訳語対抽出手法」は、解析したい「概念」が母語のデータにおいて出現する文脈を解析し、一般的に使用されている辞書を活用して出現文脈を母語から他言語に変換した上で、他言語中の似たような文脈で出現する表現を訳語の候補として抽出するしくみとなっており、解析担当者は、専門分野に関する知識を持っていれば、他言語の知識がなくても未知の言語の文書データを分析することが可能になるという。
実際のビジネスシーンでは、日本語といった一つの言語で定義された分析対象表現に対応する可能性の高い表現を、今回の「訳語対抽出手法」を使って他言語のデータから自動的に探し出し、日本語で分析する。企業はその結果をもとに、分析対象表現の出現傾向を把握し、特定の製品への偏りや急増傾向を捉えることで、まだ把握していない事実や問題点を早期に発掘し、調査のきっかけをつかんだり、適切なアクションにつなげるといった利用方法が実現可能になると見込まれている。
テキストマイニングのマイニング(mining)は、「発掘・採掘」の意味で、集められたテキストデータの山から自らのビジネスにとって有益である情報を掘り起こす意味合いがある。現状では、データ中の単語やフレーズの出現回数やそれらの相関関係を分析する手法が主流となっている。
結論を文の前に置くか後ろに置くかだけでも、英語と日本語では異なるように、キーワード以外の部分に翻訳のポイントが存在するケースも少なくない。データ全体の意味を理解しやすくなる手法が効果的であるようならば、インターネット上に散在する価値ある日本語以外の文書にも手が届くようになるだろう。
日本IBM
リリース
詳細ページ
[PR]

-->
記事検索
ユニーク特集
株式会社ファーストキャビン
変態企業カメレオン
株式会社エイタロウソフト
株式会社GABA
株式会社リクルートエージェント
らでぃっしゅぼーや株式会社
株式会社ツナグ・ソリューションズ
株式会社ネビュラプロジェクト
使えるねっと株式会社
株式会社ECC
アクセスランキング トップ10
お問い合わせ
モバイルサイトQRコード
チェッカーズ!モバイルサイトへアクセス
htt
